

Прогресс в области крупномасштабных распределенных программных систем кардинально меняет подходы в разработке ПО. Мы быстро осваиваем практики, которые увеличивают гибкость разработки и скорость развертывания. Однако возникает не менее важный вопрос: насколько уверены мы в надежности сложных систем, которые запускаем в эксплуатацию?
По данным Gremlin, бизнесы теряют миллионы долларов в час во время сбоев в системе. Каждая минута простоя высоконагруженной системы может привести к потере клиентов и ухудшению репутации бренда.
- Почему происходят сбои
- Как спланировать имитацию сбоя
- Плюсы и Минусы Хаос-Инжиниринга
- Расчет Финансовой Эффективности Хаос-Инжиниринга
- Выводы
Один из методов снижения убытков от технических инцидентов — это хаос-инжиниринг, намеренное создание сценариев отказов в бизнес-сервисах для повышения их надежности.
Цель — тестирование устойчивости приложений, выявление слабых мест и скрытых проблем в проектрировании и улучшение производительности системы в реальных условиях.
Это особенно важно для онлайн-сервисов финансовых и медицинских учреждений, телекоммуникационных, транспортных компаний, соцсетей и онлайн-магазинов.
Тестирование включает моделирование сбоев компонентов серверов, сетевой инфраструктуры или конкретных приложений. Существует стандартная модель тестирования, разработанная мировыми IT-компаниями и международным сообществом Awesome Chaos Engineering.
Почему происходят сбои
Согласно опросу Uptime Institute за 2023 год, проведенному среди 600 компаний различных отраслей, за последние три года большинство компаний сталкивались со сбоями в работе, более трети из них – серьезные инциденты повлекшие значительные убытки.
Менее половины владельцев и операторов дата-центров отслеживают метрики, необходимые для оценки устойчивости и выполнения предстоящих нормативных требований.
Частота и серьезность сбоев в дата-центрах остаются почти неизменными по сравнению с 2023 годом или демонстрируют незначительные улучшения. Операторы противостоят росту сложности, плотности и экстремальным погодным условиям благодаря инвестициям и хорошим методам управления.
Компании продолжают удовлетворять свои IT-потребности с помощью гибридных архитектур. Более половины рабочих нагрузок (55%) теперь размещены вне помещения, что продолжает постепенную тенденцию последних лет.
Основные причины:
- Проблемы сети
- Перезагрузка серверов из-за перебоев в электроснабжении
- Ошибки программного обеспечения
- Перебои в сервисах внешних IT-поставщиков
Поскольку сетевые сбои и проблемы с питанием составляют более половины всех инцидентов, риск потерь можно значительно снизить, выбирая дата-центры Tier III с уровнем доступности не менее 99,982%.
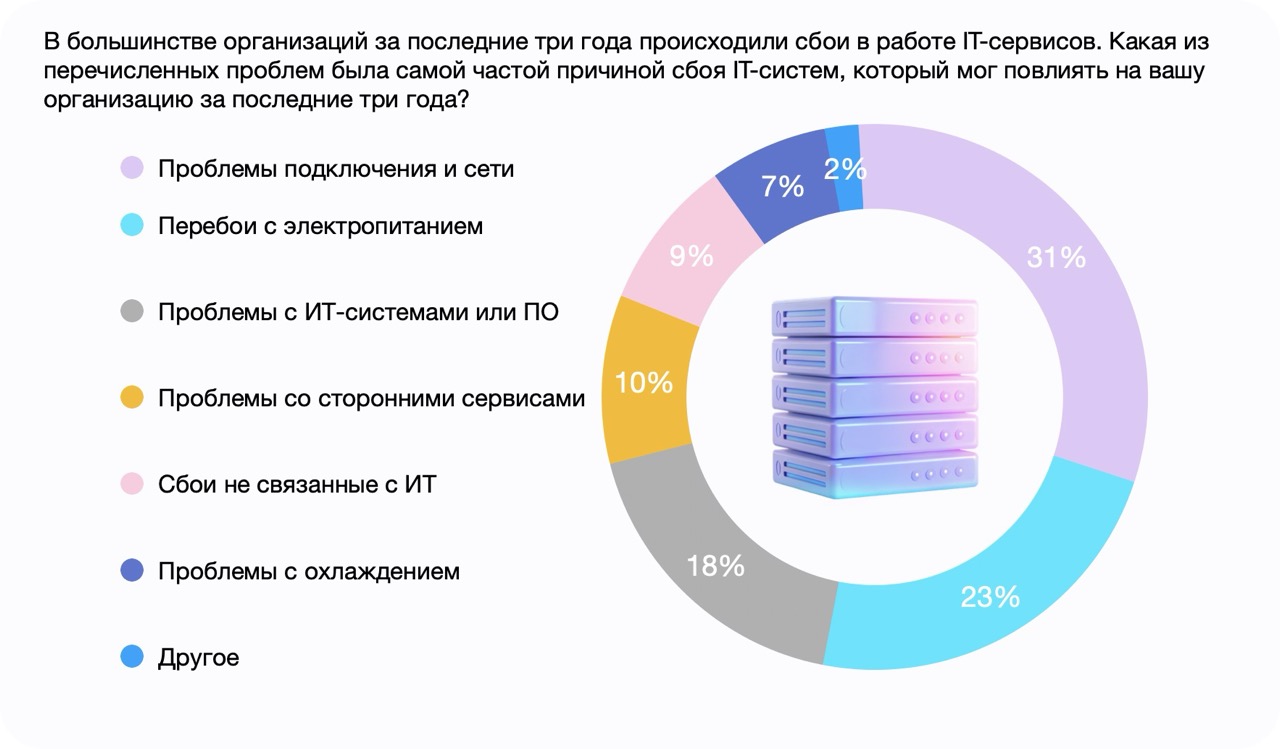
Опрос Uptime Institute о Надежности Дата-Центров 2023
Как спланировать имитацию сбоя
Фиксируем норму: что такое стабильность вашего сервиса?
Этот этап задает отправную точку, от которой мы будем оценивать любые изменения при моделировании сбоя. Все отклонения измеряются относительно этой стабильной базы.
Гипотеза из реальных происшествий: на что ставим?
За основу гипотезы берутся реальные события: сбои серверов, поломки жестких дисков или сбои в сети. Прошлые инциденты и уязвимости системы формируют сценарий для проверки.
Сценарий отказа: что происходит, когда все идет не так?
Фиксируйте каждое событие в процессе эксперимента. Эти данные помогут понять природу сбоев и принять меры для их устранения.
Итрерации: автоматизация и повторение экспериментов
Новые версии бизнес-сервиса могут скрывать неожиданные уязвимости. Постоянное моделирование позволяет обнаружить и устранить потенциальные проблемы до их появления.
Для имитации сбоя не нужны отдельные специалисты, с этой задачей могут справиться DevOps-инженеры, разработчики, инженеры поддержки или системные администраторы.
Что нужно уметь
- Работать с операционными системами, такими как Linux или Windows.
- Иметь опыт с облачными платформами, например, Kubernetes или OpenShift.
- Писать скрипты для моделирования сбоев, например, bash-скрипты в Linux.
Плюсы и Минусы Хаос-Инжиниринга
Преимущества |
Необходимые вложения
|
|
|
Расчет Финансовой Эффективности Хаос-Инжиниринга
Во-первых, учитывайте стоимость простоя сервиса. Эта цифра зависит от масштаба, сложности и специфики IT-системы. В среднем одна минута простоя в высоконагруженной системе стоит от $7,200 до $9,000, по данным Uptime Institute и Gremlin.
Чтобы рассчитать экономический эффект технического сбоя и затраты на использование хаос-инжиниринга, рассмотрите следующий сценарий: бизнес запускает новый продукт, инвестирует в рекламу, и трафик увеличивается, что приводит к перегрузке оборудования и сбою в работе сервиса.
Затраты на устранение инцидента
- Потери от инцидента: упущенная прибыль
- Аварийная команда: оплата труда 5-10 сотрудников
- Разработка временного решения: ежедневные зарплаты команды разработчиков
- Разработка постоянного решения: до 14 дней оплаты труда разработчиков
В случае хаос-инжиниринга
- Стоимость моделирования: оплата труда 1-2 сотрудников
- Разработка постоянного решения: до 14 дней оплаты труда разработчиков
- В этом случае, инвестиции в хаос-инжиниринг будут в 2-3 раза меньше, чем стоимость реального сбоя.
Выводы
Хаос-инжиниринг помогает выявить скрытые проблемы в проектировании, масштабировании и устойчивости к сбоям, что в конечном итоге снижает финансовые потери и риски во время сбоев системы.
Практика актуальна как для выбора между размещением серверов на предприятии и облачной инфраструктурой, так и для использования стратегии мультиоблака.
Стоимость проведения моделирования отказов может варьироваться в зависимости от размера и сложности бизнес-системы, в то время как стоимость реальных сбоев может достигать десятков миллионов долларов.

Есть вопрос? Напишите в чат нашим экспертам!









